Notes on Realtime Data Processing @ Facebook
Introduction
Here are my notes and personal observations from reading this 11-page paper.
The paper describes Facebook’s analogue to Google’s Millwheel data processing ecosystem. Though this is titled “realtime,” I mostly think of systems like this as being “near-time” (seconds latency vs synchronous / milliseconds latency). It’s amazing what “the next order of latency magnitude” and asynchronosity enables.
I’ve been maintaining a lot of Google abuse team’s millwheel infrastructure, so I was very curious going in as to what Facebook’s approach to this problem is. I’ll note throughout where I see similarities to Google’s approach.
Requirements of a Realtime Data System
The paper organizes five design decisions they made centered around these five requirements for realtime data systems.
- Ease of Use
- Performance
- Fault-tolerance (defined guarantees)
- Scalability
- Correctness (guarantees not violated)
Seconds Latency
Seconds latency (vs ms latency) allows the processing components to be connected via a persistent message bus for data transport. Decoupling data transport from processing is step 1 in achieving the system requirements, as it’s a separate problem with a known quantity (how quickly we can move the data). Then what they care about is how quickly and parallel-ly they can perform data computations. Decoupling means you can tell where bottlenecks are more easily, and decide better where to focus development efforts.
Four Production Pipelines
The paper sets up four production data pipeline examples to illustrate their use case for streaming systems.
- Chorus: aggregated trends pipeline. Top-k topics, demographic summary, etc.
- Mobile Analytics: realtime feedback for facebook SWEs to diagnose mobile performance & other issues.
- Page Insights: realtime (likes, reach, engagement) events for Facebook Page owners.
- Precomputing Queries: precomputation pipeline to save CPU resources.
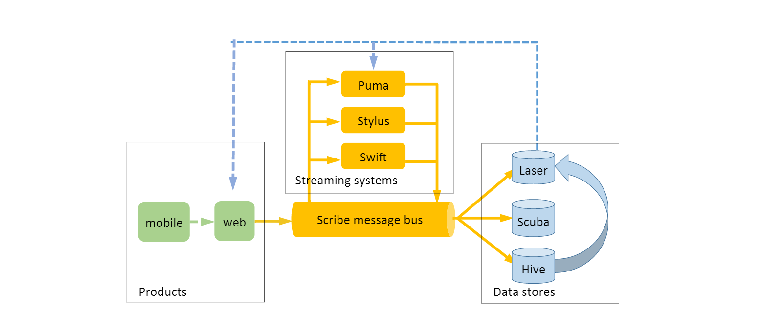
Facebook Systems Ecosystem
The paper then goes on to describe the pieces that provide, move, and store data in their system.
- Distributed Messaging: Scribe is a log transport system / pubsub I suspect is analogous to Google’s goops or LinkedIn’s Kafka. “Topics” in those systems are called “categories” in Scribe. Scribe’s persistence layer is HDFS.
- Distributed Stateful Lambdas: Puma is a Facebook system that allows users to write stateful lambdas (“stateful monoid applications”) in an SQL-like language + Java for scripting. It’s optimized for compiled queries instead of ad-hoc analysis (so very efficient query planner) and persistence is provided by a shared HBase cluster. It provides filtering for Scribe streams, and can offer neartime results to queries (delay in a query == size of query result’s time window).
- Message Checkpointing: Swift is a low-level systems library with a simple API that lets you read from the message bus (scribe) while checkpointing every N strings or B bytes. This provides fault-tolerance and at-least-once processing semantics to the overall system that is tunable by the client; Swift apps are written in scripting languages (Python). It’s good for low-throughput, stateless processing.
- Stream Processing: Stylus provides stream processing similar to computation nodes in millwheel and is also C++. It also provides an event time “low watermark estimate” (indicates an estimate of the oldest unprocessed work in the system, which gives you an idea of how “behind” actual realtime your pipeline is).
- Key-Value Storage: Laser is a RocksDB-based distributed KV storage service with high throughput and low ms latency. Puma / Stylus can both read input from Laser and output to Laser. Then products can read from Laser to access “realtime” computation results always. This is really interesting; on Google’s abuse team we have a KV store specific to abuse built on Spanner and millwheel uses it, probably similarly to Laser.
- Ad-hoc Data Querying: Scuba is comparable to Google’s plx tooling, which provides ad-hoc querying over various data inputs and gives a UI with query results in a variety of visualization formats (tables, time series, bar charts, world maps). I think it’s nice that Facebook has great UIs for their devs; I think this is one area Google’s tooling can improve. We have some tools to do these things as well but I’ve found some of them to be cumbersome; not having used Facebook’s tools I wonder if they have the same problems. That said, at an @Scale conference Facebook demo’ed some of their internal tooling UI and I was impressed. So I wouldn’t be surprised to know their internal GUIs are nice. Presto is comparable to Google’s dremel which lets you use SQL queries over stored data.
- Data Warehousing: Hive is Facebook’s data warehouse (multiple petabytes / day).
Example Streaming Pipeline @ Facebook: Chorus
Before discussing the design choices, the paper details a full-fledged streaming pipeline to clarify how each of the ecosystem pieces are used. The pipeline is to detect trends.
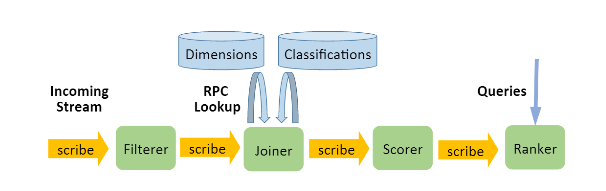
- Filterer: filters the input stream based on event type, shards output on dimension id so that the processing for the next node can be done in parallel on shards with disjoint sets of dimension IDs. Analogous to millwheel’s “adapter nodes” – difference is that sharding method is configurable rather than based on the input… do they transform their inputs if they want to shard differently? Or are they not mentioning that it’s actually more flexible than that? This is often a Puma app.
- Joiner: queries external systems to retrieve info; good sharding ensures caches are warm and minimum network calls are needed. Analogous to millwheel’s “annotator nodes.” This is implemented as a stylus node.
- Scorer: can keep sliding windows & long term trends, seems like a millwheel “aggregation node” with an “aggregation buffer.” This is also a stylus node. Interesting to me is what they use to store state in this node; Google uses Bigtable, so maybe they’re on HBase or another column store?
- Ranker: computes top-k, so another aggregator node I suppose. Arbitary computation with some state required. They can implement this in Puma or Stylus.
Design Decisions
Now the paper gets to their five design decision!! Finally!
1. Language Paradigm
2. Data Transfer
3. Processing Semantics
4. State-saving Mechanisms
5. Backfill Processing
Lessons Learned
Multiple Systems
Ease of Debugging
Ease of Deployment
Ease of Monitoring
Streaming vs Batch Processing
Not an either-or decision! Streaming systems can be created that don’t miss data (exact counts and sums), and good approximate counts (hyperloglog! count-min sketch!) are often as actionable as exact numbers. No new insights here.
Conclusions
Facebook built multiple independent but composable systems that together serve as a platform for their streaming needs; three major points.
- Seconds is fast enough for all supported use cases; allows persistent message bus as data transport.
- Ease of use is as important as other qualities!!! High learning curve sucks; Google has been tackling the same thing via Streaming Flume API for millwheel. Debugging / deployment / monitoring tools also very important & help adoption.
- Spectrum of correctness; not all use cases need ACID semantics, so a good platform provides a spectrum of choices to let application builders decide what they need. If they need transactions / exactly-once semantics, they pay via extra latency, more hardware (e.g more state is needed for exactly-once semantics).
Future work
Some things they are working on:
- Scaling: improve dynamic load balancing
- Alternate environments for stream processing backfill jobs (Spark / Flink vs Hive).